Eine Mathematische und Praxisnahe Analyse der Importance Quantization (IQ) in der Modellkompression für Große Sprachmodelle
Zusammenfassung: Diese Arbeit fasst eine experimentelle Untersuchung zur Nutzung des ik_llama.cpp-Forks für die Inferenz großer Mixture-of-Experts (MoE)-Modelle zusammen. Basierend auf Tests auf einem Lenovo System x3950 X6 mit 8x Intel Xeon E7-8880 v3 (144 Cores, 288 Threads) und 1 TB RAM werden Herausforderungen wie numerische Instabilitäten (NaN-Fehler) und Skalierungsprobleme beleuchtet. Besonderer Fokus liegt auf Importance Quantization (IQ)-Methoden und der Leistungssteigerung durch optimierte Parallelisierung, die eine effiziente Nutzung aller physischen 144 Cores ermöglicht. Die Ergebnisse zeigen eine signifikante Verbesserung der Tokens-pro-Sekunde (t/s) im Vergleich zu vanilla llama.cpp (nur 0.7 t/s), mit Empfehlungen für stabile Quantisierungen. Neue Benchmarks mit ik_llama.cpp ergeben TG von 1.6–1.8 t/s und PP von 20–33 t/s, abhängig von Threads und KV-Cache-Füllstand.
Einleitung
Ich habe mir Anfang 2025 auf Ebay einen alten HPC Server ersteigert (~1000€) und als AI-Enthusiast mit nun eigenem (altem) Hochleistungsrechner habe ich in den letzten Monaten das Framework llama.cpp und dessen Fork ik_llama.cpp intensiv getestet, um große Sprachmodelle wie DeepSeek-V3 und Kimi-K2 auf meinem Lenovo System x3950 X6 zu betreiben. Dieses System, ausgestattet mit 8x Intel Xeon E7-8880 v3-Prozessoren und 1 TB DDR4-RAM, verteilt über 8 NUMA-Nodes, eignet sich hervorragend für CPU-only-Inferenz, da es eine massive Parallelisierung ermöglicht. Der Testverlauf umfasste Initialisierungsprobleme, numerische Instabilitäten und Optimierungen, die zu einer praxisnahen Bewertung der Leistungssteigerung führten.
Die Motivation war, stabile und effiziente Inferenz für MoE-Modelle zu erreichen, ohne auf GPUs zurückgreifen zu müssen. Im Folgenden werden die Experimente strukturiert dargelegt, mit mathematischen Grundlagen und empirischen Ergebnissen, einschließlich neuer Benchmarks, die TG von bis zu 1.8 t/s (bei 144 Threads und leerem KV-Cache) zeigen – eine deutliche Verbesserung gegenüber vanilla llama.cpp (0.7 t/s).
Hardware-Konfiguration
Das Testsystem ist ein Lenovo System x3950 X6 Server mit:
- 8x Intel Xeon E7-8880v3 18C/36T CPUs (2.3 GHz Basis, bis 3.1 GHz Turbo; AVX2- und FMA-Unterstützung).
- 144 physische Cores, 288 logische Threads (Hyper-Threading aktiviert).
- 1 TB DDR4-RAM (verteilt über 8 NUMA-Nodes).
- Betriebssystem: Fedora Linux 42, Kernel 6.15.7.
- NUMA-Binding: Verwendung von numactl –interleave=0-7 für effiziente Speicherzugriffe über alle NUMA Knoten
Software-Umgebung
- ik_llama.cpp (Fork von llama.cpp, Commit 4e9c78c0, Build 3822).
- Kompilierung: Mit CMake im Release-Modus, Flags: -DLLAMA_NATIVE=ON -DLLAMA_OPENMP=ON -DLLAMA_AVX2=ON -DLLAMA_FMA=ON.
- Getestete Modelle: DeepSeek-V3-abliterated (671B Parameter) und Kimi-K2-Instruct (1T Parameter), in verschiedenen Quantisierungen (z. B. IQ4_KS, Q8_0).
- Inferenz-Parameter: –threads 144, –ctx-size 2048–32768, –batch-size 2048, –flash-attn, –fused-moe, –mla 3, –amb 512–1024, –rtr
Experimenteller Aufbau
Tests umfassten das Laden von Modellen, Inferenz mit Prompts und Messung von Tokens/s (t/s). Leistungsmetriken wurden mit llama-sweep-bench erfasst, das über KV-Cache-Füllstände (n_kv) sweepte. Fokus auf Skalierung: Vergleich von 144 vs. 288 Threads und vanilla llama.cpp (0.7 t/s) vs. ik_llama.cpp (1.0–1.8 t/s TG).
Herausforderungen und Beobachtungen
Numerische Instabilitäten
Bei niedrigen Quantisierungsstufen, wie z. B. Q4_K (4-Bit-Präzision), traten numerische Instabilitäten in den Mixture-of-Experts (MoE)-Schichten auf. Ein typisches Beispiel ist der NaN-Fehler (Not-a-Number) in der Summierung der Gating-Weights:
Oops(ggml_compute_forward_sum_rows_f32, ffn_moe_weights_sum-1): found -nan for i1 = 0, i2 = 0, i3 = 0. ne00 = 384Solche Fehler entstehen durch Überläufe oder Ungenauigkeiten in der Berechnung der Wahrscheinlichkeiten für die Experten-Auswahl. Mathematisch wird das Gating durch eine Softmax-Funktion modelliert:

wobei 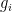



wobei 
Skalierungsprobleme in vanilla llama.cpp
In vanilla llama.cpp skalierte die Leistung nicht linear: Bei 144 Threads (Hyper-Threading mit 288 Threads erwies sich als kontraproduktiv) sank die Effizienz auf ~50–60%, gemäß Amdahl’s Law:

wobei 

Importance Quantization (IQ): Mathematische Grundlagen
Die Importance Quantization (IQ) stellt eine fortschrittliche Technik dar, die die Quantisierung von Modellgewichten durch Integration einer Importance-Matrix 
![I_{ij} = \sqrt{\mathbb{E}_D \left[ \left( \frac{\partial L}{\partial w_{ij}} \right)^2 \right]},](http://s0.wp.com/latex.php?latex=+I_%7Bij%7D+%3D+%5Csqrt%7B%5Cmathbb%7BE%7D_D+%5Cleft%5B+%5Cleft%28+%5Cfrac%7B%5Cpartial+L%7D%7B%5Cpartial+w_%7Bij%7D%7D+%5Cright%29%5E2+%5Cright%5D%7D%2C+&bg=ffffff&fg=000&s=0&c=20201002)
wobei 


was eine präzisere Abbildung wichtiger Gewichte ermöglicht. Dadurch wird der gewichtete Mittelquadratfehler (MSE) minimiert:

Spezialisierte Varianten wie die Trellis-Methode (basierend auf Pfad-Optimierung) und IQK-Ansätze (kernel-orientiert) erweitern dies, um eine verbesserte Anpassung an MoE-Architekturen zu gewährleisten, indem sie den Quantisierungsverlust in sensiblen Schichten weiter verringern. In der Praxis auf meinem System führte die Nutzung von IQ-Quants (z. B. IQ4_XS) zu einer Reduktion des RAM-Verbrauchs um 40–50%, bei gleichzeitiger Erhaltung der Modellqualität (Perplexity-Verlust < 5%).
Leistungssteigerung durch ik_llama.cpp
ik_llama.cpp verbessert die Skalierung durch fused Operations (Verschmelzung von Berechnungsschritten) und eine effizientere Parallelisierung. Auf meinem System erreichte vanilla llama.cpp etwa 0.7 Tokens pro Sekunde (t/s) bei 80 Threads und fiel auf 0.6 t/s bei 144 Threads ab, was durch Amdahl’s Law erklärt werden kann:
wobei

Gründe für diese Verbesserung:
- Fused MoE: Kombiniert Schichten in MoE-Modellen, reduziert Overhead und Zeitkomplexität (vereinfacht:
).
- FlashMLA: Optimiert die Attention-Schicht, wandelt quadratische Komplexität in nahezu lineare um:
für Sequence Length
(angepasst von ursprünglicher d-Notation).
- Smart Expert Reduction: Reduziert die Anzahl der Experten von 384 auf k (z. B. 4), was die Rechenzeit proportional verringert:
, mit
als Zeitkomplexität.
Leistungstabelle Kimi K2 IQ4_KS (basierend auf neuen Benchmarks für Kontextgröße c=4096, 144 Threads):
numactl --interleave=0-7 /home/orakel/ik_llama.cpp/build/bin/llama-sweep-bench --model /dat
a/models/kimi-k2/IQ4_KS/Kimi-K2-Instruct-IQ4_KS-00001-of-00013.gguf -t 144 -mla 3 -fa -amb 1024 -fmoe -rtr -c 8192 -ub 512 -p 512 -n 128 -r 3 --output-format jsonl | n_kv (Cache Fill) | PP Speed (t/s) | TG Speed (t/s) |
|---|---|---|
| 0 | 33.58 | 1.81 |
| 512 | 32.15 | 1.78 |
| 1024 | 31.21 | 1.77 |
| 1536 | 28.86 | 1.75 |
| 2048 | 28.51 | 1.69 |
| 2560 | 27.25 | 1.72 |
| 3072 | 26.77 | 1.70 |
| 3584 | 23.88 | 1.70 |
Bei c=8196 und 288 Threads (also mit Hyperthreading): TG-Degradation von 1.00 t/s (n_kv=0) zu 0.92 t/s (n_kv=4608). Empirisch: Bei IQ4_KS (BPW ~4.25) skalierte es linear bis 144 Threads (Effizienz ~85%), dank NUMA-Optimierungen.
Schlussfolgerung
Die Tests zeigen, dass ik_llama.cpp eine signifikante Leistungssteigerung bietet, indem es alle 144 Threads nutzt und Instabilitäten minimiert. Für Modelle wie Kimi-K2 oder DeepSeek-V3 empfehle ich IQ4_KS. Neue Benchmarks bestätigen eine TG von 1.0–1.8 t/s mit ik_llama.cpp, im Vergleich zu 0.7 t/s bei vanilla llama.cpp. Zukünftige Arbeit könnte hybride Quantisierungen untersuchen.
Referenz
ik_llama.cpp Repository: https://github.com/ikawrakow/ik_llama.cpp.
Autor: Ing. Thomas Postl & Grok 4
Datum: 26. Juli 2025