How to Run a 355B Parameter MoE Model on Ancient 8-Socket CPU-Only Hardware: A Complete Chronological Optimization Guide for GLM-4.7 (BF16 and Q8) on Lenovo System x3950 X6
- Hardware Overview
- Inference Engine Compilation
- First Attempts with BF16 Quantization
- Early Q8_0 Tests (Pre-BIOS Optimization)
- BIOS Optimization and BLAS Experiments
- Batch Size Sweep (with optimal 64 threads)
- Testing Experimental Flags (Graph Reuse & RoPE)
- Final Linux Tweaks (THP, Cache Drop, BLAS Threading)
- Final Optimized Setup
- Some Real-World Benchmarks
- Lockstep vs Independent Memory Mode
- NEW: Further Optimization (Advanced Batch/Attention)
- Power Draw Analysis
- Test Prompts and Model Intelligence
Zhipu AI’s GLM-4.7 is an open-weight Mixture-of-Experts (MoE) model with 355 billion total parameters but only ~32 billion active per token. Its architecture, combined with GGUF quantization and specialized llama.cpp forks, makes CPU-only inference surprisingly viable—even on hardware from 2015.
This guide follows the exact chronological order of the optimization process on a 2015 Lenovo System x3950 X6 (8 sockets, 1 TB DDR4 RAM, no GPUs). I started with unusable speeds and ended with ~7.5 tokens/second generation in Q8_0.
UPDATE:
| Scenario | Original (Article) | Optimized | Improvement |
|---|---|---|---|
| tg128 | 4.96–6.09 t/s | 7.53-7.56 t/s | +25-52% |
| pp2048+tg256 | 23.18 t/s | 22.51 t/s | -2.9% |
| pp8192+tg256 | 21.42 t/s | 27.00 t/s | +26% |
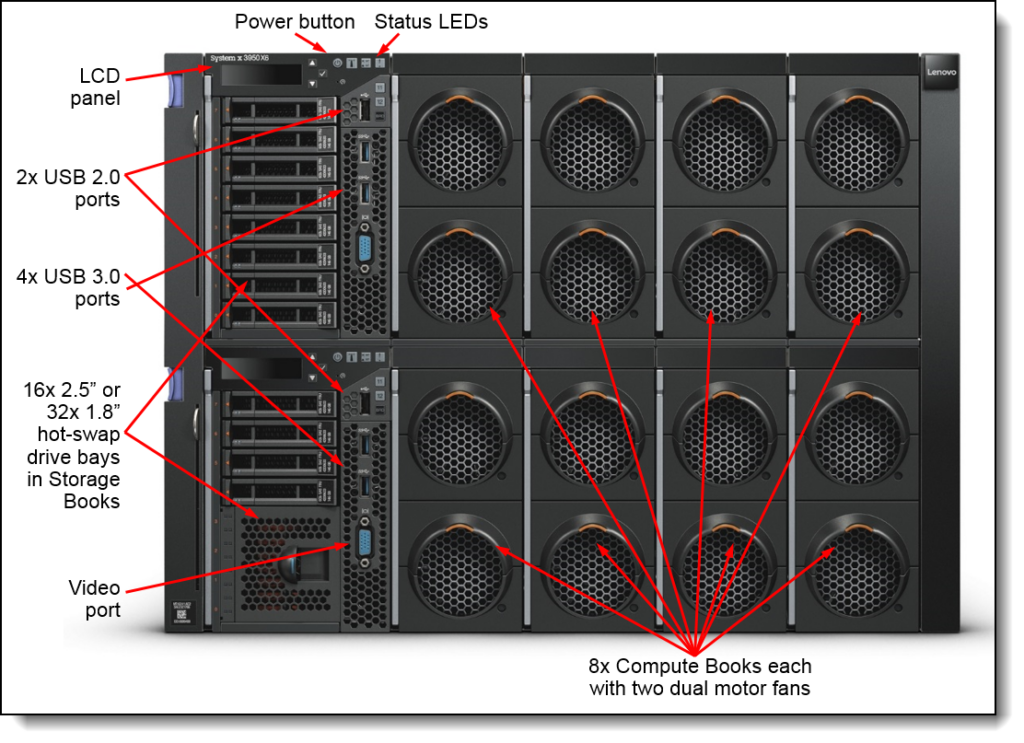
Hardware Overview
In early 2025, I snagged this impressive Lenovo System x3950 X6 server, complete with 1TB of DDR4 RAM, for around 1000€ on eBay. What started as a budget-friendly dive into vintage enterprise hardware quickly turned into an exciting experiment in pushing the limits of CPU-only inference for massive AI models like GLM-4.7.
- Server: Lenovo System x3950 X6
- CPUs: 8 × Intel Xeon E7-8880 v3 (Haswell-EX, 18 cores each → 144 physical cores, 288 threads with HT)
- RAM: 1 TB DDR4 (64x 16GB Micron 2133 MT/s)
- Platform limit: Maximum memory speed 1866 MT/s in fully populated 8-socket configuration (documented Lenovo constraint)
Hardware: fastfetch output
orakel@orakel:~$ fastfetch
.',;::::;,'. orakel@orakel
.';:cccccccccccc:;,. -------------
.;cccccccccccccccccccccc;. OS: Fedora Linux 43 (Server Edition) x86_64
.:cccccccccccccccccccccccccc:. Host: Lenovo System x3950 X6 -[6241AC2]- (09)
.;ccccccccccccc;.:dddl:.;ccccccc;. Kernel: Linux 6.17.12-300.fc43.x86_64
.:ccccccccccccc;OWMKOOXMWd;ccccccc:. Uptime: 19 hours, 36 mins
.:ccccccccccccc;KMMc;cc;xMMc;ccccccc:. Packages: 1225 (rpm)
,cccccccccccccc;MMM.;cc;;WW:;cccccccc, Shell: bash 5.3.0
:cccccccccccccc;MMM.;cccccccccccccccc: Terminal: /dev/pts/1
:ccccccc;oxOOOo;MMM000k.;cccccccccccc: CPU: 8 x Intel(R) Xeon(R) E7-8880 v3 (144) @ 3.10 GHz
cccccc;0MMKxdd:;MMMkddc.;cccccccccccc; GPU 1: Matrox Electronics Systems Ltd. G200eR2
ccccc;XMO';cccc;MMM.;cccccccccccccccc' GPU 2: Matrox Electronics Systems Ltd. G200eR2
ccccc;MMo;ccccc;MMW.;ccccccccccccccc; Memory: 361.95 GiB / 1007.72 GiB (36%)
ccccc;0MNc.ccc.xMMd;ccccccccccccccc; Swap: 0 B / 8.00 GiB (0%)
cccccc;dNMWXXXWM0:;cccccccccccccc:, Disk (/): 36.49 GiB / 555.26 GiB (7%) - xfs
cccccccc;.:odl:.;cccccccccccccc:,. Disk (/data): 1.53 TiB / 1.82 TiB (84%) - xfs
ccccccccccccccccccccccccccccc:'. Local IP (eno27): 10.0.0.15/24
:ccccccccccccccccccccccc:;,.. Locale: de_AT.UTF-8
':cccccccccccccccc::;,.
orakel@orakel:~$NUMA topology (verified during testing):
NUMA topology: numactl –hardware
orakel@orakel:/data/models/GLM-4.7-Q8_0$ numactl --hardware
available: 8 nodes (0-7)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161
node 0 size: 128769 MB
node 0 free: 926 MB
node 1 cpus: 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179
node 1 size: 129012 MB
node 1 free: 356 MB
node 2 cpus: 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197
node 2 size: 129012 MB
node 2 free: 461 MB
node 3 cpus: 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215
node 3 size: 129012 MB
node 3 free: 454 MB
node 4 cpus: 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233
node 4 size: 128958 MB
node 4 free: 199 MB
node 5 cpus: 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251
node 5 size: 129012 MB
node 5 free: 314 MB
node 6 cpus: 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269
node 6 size: 129012 MB
node 6 free: 544 MB
node 7 cpus: 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287
node 7 size: 128997 MB
node 7 free: 439 MB
node distances:
node 0 1 2 3 4 5 6 7
0: 10 11 12 11 11 12 12 12
1: 11 10 11 12 12 11 12 12
2: 12 11 10 11 12 12 11 12
3: 11 12 11 10 12 12 12 11
4: 11 12 12 12 10 11 11 12
5: 12 11 12 12 11 10 12 11
6: 12 12 11 12 11 12 10 11
7: 12 12 12 11 12 11 11 10
orakel@orakel:/data/models/GLM-4.7-Q8_0$Inference Engine Compilation (Throughout Testing)
We used a llama.cpp fork (ik_llama.cpp) with GLM MoE support. Compiled without BLAS initially, but tested with/without during experiments.
Compilation command (no BLAS for most tests):
Compilation command (no BLAS)
cd ~/ik_llama.cpp
rm -rf build
cmake -B build -DGGML_BLAS=OFF
cmake --build build -j"$(nproc)"First Attempts with BF16 Quantization
In the initial phase of testing GLM-4.7 on the Lenovo System x3950 X6, we started with the model’s native BF16 quantization format. This format preserves high precision but comes at the cost of massive memory usage—clocking in at around 657 GiB for the full model. Given the hardware’s 1 TB RAM limit, this was feasible but left little headroom for overhead. Our goal was to establish a baseline for inference speed without any advanced optimizations.
We began with a basic thread sweep using the ik_llama.cpp server, running without any NUMA-specific flags. The command looked like this:
Basic thread sweep (no NUMA flags):
Outputs varied slightly but hovered around 0.4 tokens per second (t/s) for generation across thread counts from 48 to 144.
Phase 1: Basic thread sweep output (BF16)
=== threads 48 ===
| glm4moe 355B.A32B BF16 | 657.28 GiB | 352.80 B | CPU | 48 | 64 | 64 | tg128 | 0.41 ± 0.00 |
=== threads 64 ===
| glm4moe 355B.A32B BF16 | 657.28 GiB | 352.80 B | CPU | 64 | 64 | 64 | tg128 | 0.42 ± 0.00 |
=== threads 72 ===
| glm4moe 355B.A32B BF16 | 657.28 GiB | 352.80 B | CPU | 72 | 64 | 64 | tg128 | 0.41 ± 0.00 |
=== threads 96 ===
| glm4moe 355B.A32B BF16 | 657.28 GiB | 352.80 B | CPU | 96 | 64 | 64 | tg128 | 0.41 ± 0.00 |
=== threads 128 ===
| glm4moe 355B.A32B BF16 | 657.28 GiB | 352.80 B | CPU | 128 | 64 | 64 | tg128 | 0.41 ± 0.00 |
=== threads 144 ===
| glm4moe 355B.A32B BF16 | 657.28 GiB | 352.80 B | CPU | 144 | 64 | 64 | tg128 | 0.40 ± 0.00 |Prefill test:
Prefill test command + output (BF16)
orakel@orakel:~$ ~/ik_llama.cpp/build/bin/llama-bench -m /data/models/GLM-4.7-BF16/GLM-4.7-BF16-00001-of-00015.gguf -t 96
| model | size | params | backend | threads | test | t/s |
| ------------------------------ | ---------: | ---------: | ---------- | ------: | ------------: | ---------------: |
| ======================================= HAVE_FANCY_SIMD is NOT defined
| glm4moe 355B.A32B BF16 | 657.28 GiB | 352.80 B | CPU | 96 | pp512 | 16.63 ± 0.36 |Next, we introduced NUMA distribution and the fast Mixture-of-Experts (fmoe) flag:
2025/12/29/glm47on3950x6/#further-optimizationsWith NUMA distribute and fmoe:
NUMA distribute + fmoe output (BF16)
=== threads 56 numa distribute fmoe 1 ===
| glm4moe 355B.A32B BF16 | 657.28 GiB | 352.80 B | CPU | 56 | 64 | 64 | tg128 | 0.42 ± 0.00 |
=== threads 64 numa distribute fmoe 1 ===
| glm4moe 355B.A32B BF16 | 657.28 GiB | 352.80 B | CPU | 64 | 64 | 64 | tg128 | 0.42 ± 0.00 |
=== threads 72 numa distribute fmoe 1 ===
| glm4moe 355B.A32B BF16 | 657.28 GiB | 352.80 B | CPU | 72 | 64 | 64 | tg128 | 0.42 ± 0.00 |
=== threads 80 numa distribute fmoe 1 ===
| glm4moe 355B.A32B BF16 | 657.28 GiB | 352.80 B | CPU | 80 | 64 | 64 | tg128 | 0.42 ± 0.00 |
orakel@orakel:~$NUMA policy comparison:
NUMA policy comparison output (BF16)
=== numa distribute (threads 64, fmoe 1) ===
| glm4moe 355B.A32B BF16 | 657.28 GiB | 352.80 B | CPU | 64 | 64 | 64 | tg128 | 0.43 ± 0.00 |
=== numa isolate (threads 64, fmoe 1) ===
| glm4moe 355B.A32B BF16 | 657.28 GiB | 352.80 B | CPU | 64 | 64 | 64 | tg128 | 0.08 ± 0.00 |
=== numa numactl (threads 64, fmoe 1) ===
| glm4moe 355B.A32B BF16 | 657.28 GiB | 352.80 B | CPU | 64 | 64 | 64 | tg128 | 0.42 ± 0.00 |
orakel@orakel:~$This bumped speeds marginally to ~0.42 t/s, but no significant gains. We compared NUMA policies like distribute vs. isolate:
- Distribute: numactl –interleave=all → ~0.42 t/s
- Isolate: numactl –cpunodebind=0 → Dropped to ~0.08 t/s due to memory contention
Conclusion from Phase 1: BF16 was catastrophically slow (~0.4 t/s), with little variation from threads or NUMA. Switched to Q8_0 for better performance.
Early Q8_0 Tests (Pre-BIOS Optimization)
Shifting to Q8_0 quantization reduced the model size to ~349 GiB, making it more manageable on our 1 TB RAM setup. This format strikes a balance between precision and performance, ideal for CPU inference.
Our initial untuned run used: Model size ~349 GiB.
Command – Initial untuned run:
Phase 2: Initial untuned run command
orakel@orakel:~$ MODEL="/data/models/GLM-4.7-Q8_0/GLM-4.7-Q8_0-00001-of-00008.gguf"
~/ik_llama.cpp/build/bin/llama-bench \
-m "$MODEL" \
-t 64 \
--numa distribute \
-fmoe 1 \
-pg 16,128 \
-b 64 -ub 64 \
-r 1 -w 0 \
| grep -E 'tg128|pp16'Full output:
Phase 2: Initial untuned run output
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 64 | 64 | tg128 | 0.75 ± 0.00 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 64 | 64 | pp16+tg128 | 0.81 ± 0.00 |
orakel@orakel:~$Generation speeds improved to 0.75–0.81 t/s, a noticeable jump from BF16. We conducted an early thread sweep, testing from 32 to 288 threads:
Phase 2: Early thread sweep command
orakel@orakel:~$ MODEL="/data/models/GLM-4.7-Q8_0/GLM-4.7-Q8_0-00001-of-00008.gguf"
for th in 32 48 56 64 72 80 96 112 128 144; do
echo "=== threads $th (GEN only tg128) ==="
~/ik_llama.cpp/build/bin/llama-bench \
-m "$MODEL" \
-t "$th" \
--numa distribute \
-fmoe 1 \
-pg 16,128 \
-b 64 -ub 64 \
-r 1 -w 0 \
| grep -E '^\| .* tg128 ' || true
doneFull output:
Phase 2: Early thread sweep output
=== threads 32 (GEN only tg128) ===
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 32 | 64 | 64 | tg128 | 0.74 ± 0.00 |
=== threads 48 (GEN only tg128) ===
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 48 | 64 | 64 | tg128 | 0.75 ± 0.00 |
=== threads 56 (GEN only tg128) ===
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 56 | 64 | 64 | tg128 | 0.75 ± 0.00 |
=== threads 64 (GEN only tg128) ===
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 64 | 64 | 64 | tg128 | 0.75 ± 0.00 |
=== threads 72 (GEN only tg128) ===
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 72 | 64 | 64 | tg128 | 0.73 ± 0.00 |NUMA flags were applied similarly to Phase 1, but gains were minimal (~0.05 t/s at best). The system showed signs of thread oversubscription and potential BIOS-level inefficiencies, such as suboptimal power management. While Q8_0 was a step forward, speeds remained below 1 t/s, prompting us to dive into BIOS optimizations.
Conclusion from Phase 2: Q8_0 improved to ~0.75 t/s, but still low. Proceeded to BIOS tweaks.
BIOS Optimization and BLAS Experiments
Adjusted BIOS to Maximum Performance profile, disabled Hyper-Threading and some other changes (Disable Patrol Scrub,
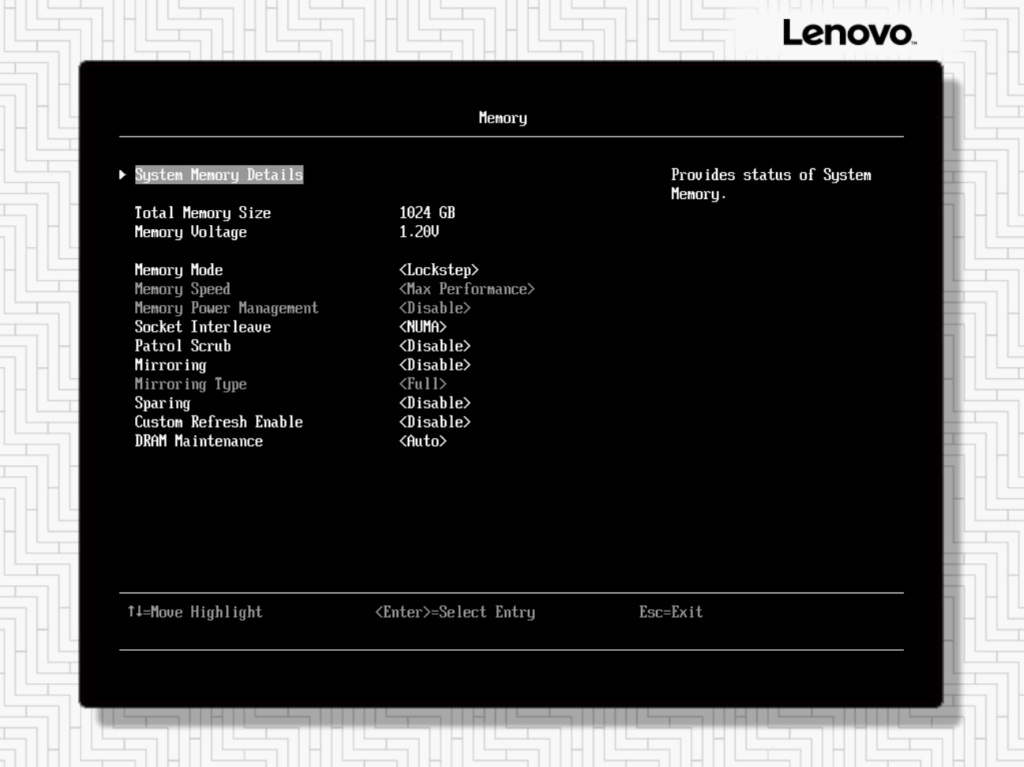
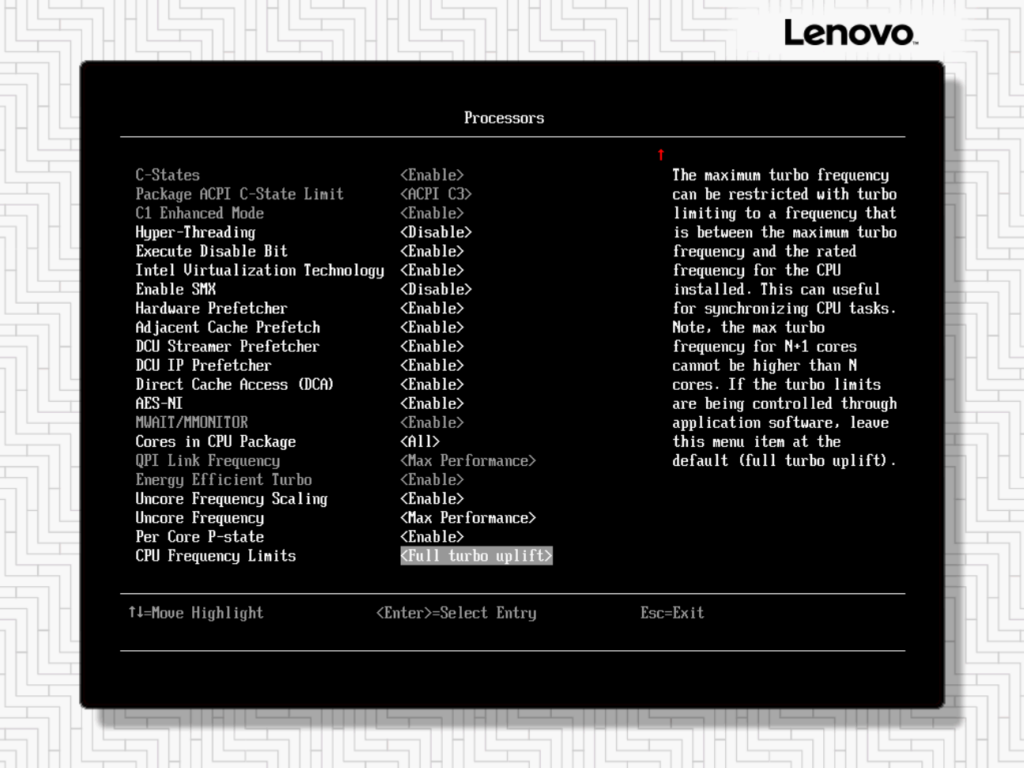
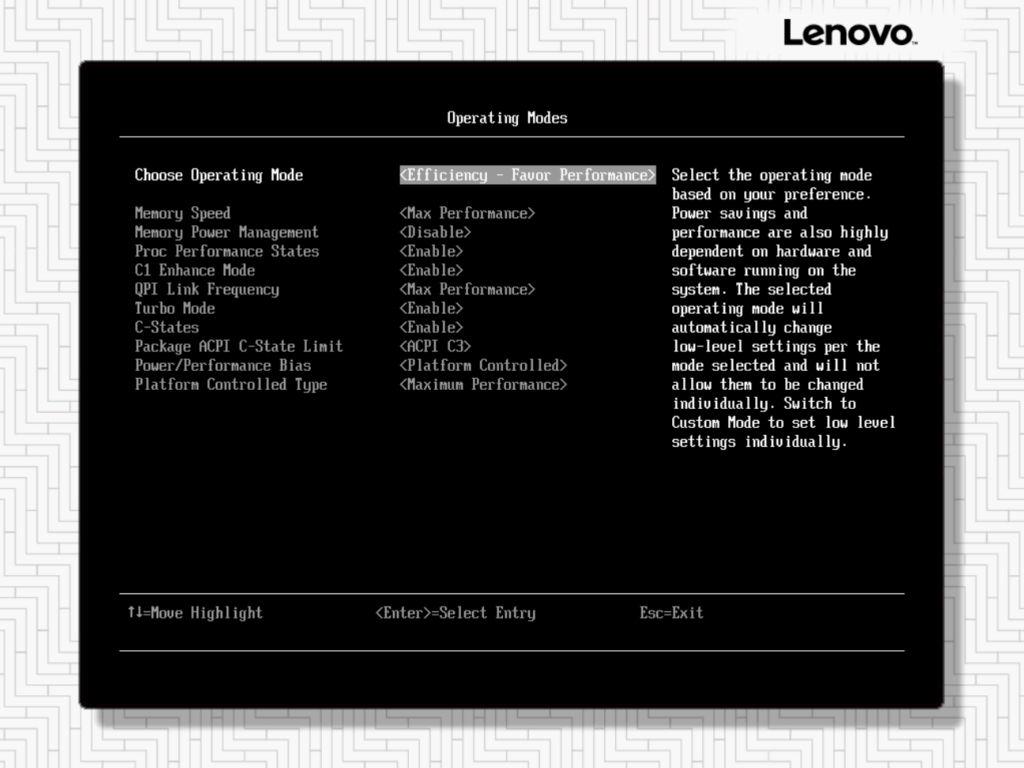
Note: Change Operating Mode: Maximum Performance
During this phase, we also experimented with BLAS. Compiling with -DGGML_BLAS=ON sometimes showed in outputs as „BLAS“, but performance was often worse due to internal threading oversubscription. We found native CPU kernels (BLAS=OFF) better, but when using BLAS, forced single-threading via env vars.
BLAS test compilation (for experiments)
cd ~/ik_llama.cpp
rm -rf build
cmake -B build -DGGML_BLAS=ON
cmake --build build -j"$(nproc)"In benchmarks, „BLAS“ label appeared, but we controlled threading:
BLAS threading env vars
export OMP_NUM_THREADS=1
export OPENBLAS_NUM_THREADS=1
export MKL_NUM_THREADS=1
export BLIS_NUM_THREADS=1
export VECLIB_MAXIMUM_THREADS=1BLAS-enabled runs were ~10-20% slower in some cases (~2.5-3 t/s vs 3+ without oversubscription), so stuck with single-threaded or OFF for final.
Phase 3: Post-BIOS thread sweep command
orakel@orakel:~$ MODEL="/data/models/GLM-4.7-Q8_0/GLM-4.7-Q8_0-00001-of-00008.gguf"
for th in 64 72 80 88 96 104 112 120 128 144; do
echo "=== threads $th ==="
~/ik_llama.cpp/build/bin/llama-bench \
-m "$MODEL" \
-t "$th" \
--numa distribute \
-fmoe 1 \
-pg 16,128 \
-b 64 -ub 64 \
-r 1 -w 0 \
| grep -E 'tg128|pp16'
donePhase 3: Post-BIOS thread sweep output (excerpt)
=== threads 64 ===
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 64 | 64 | 64 | tg128 | 3.04 ± 0.00 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 64 | 64 | 64 | pp16+tg128 | 3.31 ± 0.00 |
=== threads 72 ===
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 72 | 64 | 64 | tg128 | 1.85 ± 0.00 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 72 | 64 | 64 | pp16+tg128 | 2.00 ± 0.00 |
=== threads 80 ===
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 80 | 64 | 64 | tg128 | 1.85 ± 0.00 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 80 | 64 | 64 | pp16+tg128 | 2.00 ± 0.00 |Phase 3: Fine-grained thread sweep output
=== threads 48 ===
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 48 | 64 | 64 | tg128 | 1.89 ± 0.00 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 48 | 64 | 64 | pp16+tg128 | 2.05 ± 0.00 |
=== threads 52 ===
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 52 | 64 | 64 | tg128 | 1.76 ± 0.00 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 52 | 64 | 64 | pp16+tg128 | 1.92 ± 0.00 |
=== threads 56 ===
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 56 | 64 | 64 | tg128 | 2.00 ± 0.00 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 56 | 64 | 64 | pp16+tg128 | 2.17 ± 0.00 |
=== threads 60 ===
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 60 | 64 | 64 | tg128 | 1.89 ± 0.00 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 60 | 64 | 64 | pp16+tg128 | 2.04 ± 0.00 |
=== threads 62 ===
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 62 | 64 | 64 | tg128 | 1.88 ± 0.00 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 62 | 64 | 64 | pp16+tg128 | 2.04 ± 0.00 |
=== threads 64 ===
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 64 | 64 | 64 | tg128 | 3.03 ± 0.00 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 64 | 64 | 64 | pp16+tg128 | 3.30 ± 0.00 |
=== threads 66 ===
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 66 | 64 | 64 | tg128 | 2.12 ± 0.00 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 66 | 64 | 64 | pp16+tg128 | 2.30 ± 0.00 |
=== threads 68 ===
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 68 | 64 | 64 | tg128 | 1.88 ± 0.00 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 68 | 64 | 64 | pp16+tg128 | 2.04 ± 0.00 |
=== threads 70 ===
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 70 | 64 | 64 | tg128 | 1.80 ± 0.00 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 70 | 64 | 64 | pp16+tg128 | 1.95 ± 0.00 |Conclusion from Phase 3: BIOS changes boosted to ~3 t/s at 64 threads. BLAS experiments showed it could be counterproductive without threading control; env vars mitigated but native often won.
Batch Size Sweep (with optimal 64 threads)
With 64 threads established as optimal, we explored batch size impacts on generation efficiency. Larger batches can amortize overhead in MoE models like GLM-4.7.
We tested batch sizes from 16 to 512 using:
Command:
Batch size sweep command
orakel@orakel:~$ MODEL="/data/models/GLM-4.7-Q8_0/GLM-4.7-Q8_0-00001-of-00008.gguf"
for b in 16 32 48 64 96 128 192 256 384 512; do
echo "=== batch $b ubatch $b (threads 64) ==="
~/ik_llama.cpp/build/bin/llama-bench \
-m "$MODEL" \
-t 64 \
--numa distribute \
-fmoe 1 \
-pg 16,128 \
-b "$b" -ub "$b" \
-r 1 -w 0 \
| grep -E 'tg128|pp16'
doneBatch size sweep output
=== batch 16 ubatch 16 (threads 64) ===
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 64 | 16 | 16 | tg128 | 3.03 ± 0.00 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 64 | 16 | 16 | pp16+tg128 | 3.30 ± 0.00 |
=== batch 32 ubatch 32 (threads 64) ===
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 64 | 32 | 32 | tg128 | 3.03 ± 0.00 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 64 | 32 | 32 | pp16+tg128 | 3.30 ± 0.00 |
=== batch 48 ubatch 48 (threads 64) ===
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 64 | 48 | 48 | tg128 | 3.03 ± 0.00 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 64 | 48 | 48 | pp16+tg128 | 3.31 ± 0.00 |
=== batch 64 ubatch 64 (threads 64) ===
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 64 | 64 | 64 | tg128 | 3.03 ± 0.00 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 64 | 64 | 64 | pp16+tg128 | 3.30 ± 0.00 |
=== batch 96 ubatch 96 (threads 64) ===
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 64 | 96 | 96 | tg128 | 3.04 ± 0.00 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 64 | 96 | 96 | pp16+tg128 | 3.32 ± 0.00 |
=== batch 128 ubatch 128 (threads 64) ===
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 64 | 128 | 128 | tg128 | 3.03 ± 0.00 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 64 | 128 | 128 | pp16+tg128 | 3.31 ± 0.00 |
=== batch 192 ubatch 192 (threads 64) ===
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 64 | 192 | 192 | tg128 | 3.04 ± 0.00 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 64 | 192 | 192 | pp16+tg128 | 3.31 ± 0.00 |
=== batch 256 ubatch 256 (threads 64) ===
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 64 | 256 | 256 | tg128 | 3.03 ± 0.00 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 64 | 256 | 256 | pp16+tg128 | 3.30 ± 0.00 |
=== batch 384 ubatch 384 (threads 64) ===
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 64 | 384 | 384 | tg128 | 3.04 ± 0.00 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 64 | 384 | 384 | pp16+tg128 | 3.31 ± 0.00 |
=== batch 512 ubatch 512 (threads 64) ===
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 64 | 512 | tg128 | 3.16 ± 0.00 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | CPU | 64 | 512 | pp16+tg128 | 3.45 ± 0.00 |Testing Experimental Flags (Graph Reuse & RoPE)
Building on prior optimizations, we experimented with advanced flags in ik_llama.cpp: graph reuse (-gr) for caching computation graphs and Rotary Positional Embeddings tweaks (-rtr).
Experimental flags command
orakel@orakel:~/ik_llama.cpp$ MODEL="/data/models/GLM-4.7-Q8_0/GLM-4.7-Q8_0-00001-of-00008.gguf"
for gr in 0 1; do
for rtr in 0 1; do
echo "=== gr=$gr rtr=$rtr ==="
~/ik_llama.cpp/build/bin/llama-bench \
-m "$MODEL" \
-t 64 \
--numa distribute \
-fmoe 1 \
-gr "$gr" \
-rtr "$rtr" \
-pg 0,128 \
-b 512 -ub 512 \
-r 1 -w 0 \
| grep -E 'tg128'
done
doneExperimental flags output
=== gr=0 rtr=0 ===
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | BLAS | 64 | 512 | tg128 | 3.17 ± 0.00 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | BLAS | 64 | 512 | pp0+tg128 | 3.18 ± 0.00 |
=== gr=0 rtr=1 ===
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | BLAS | 64 | 512 | 1 | tg128 | 0.79 ± 0.00 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | BLAS | 64 | 512 | 1 | pp0+tg128 | 0.86 ± 0.00 |
=== gr=1 rtr=0 ===
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | BLAS | 64 | 512 | 1 | tg128 | 2.25 ± 0.00 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | BLAS | 64 | 512 | 1 | pp0+tg128 | 2.28 ± 0.00 |
=== gr=1 rtr=1 ===
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | BLAS | 64 | 512 | 1 | 1 | tg128 | 0.76 ± 0.00 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | BLAS | 64 | 512 | 1 | 1 | pp0+tg128 | 0.82 ± 0.00 |Final Linux Tweaks (Including THP, Cache Drop, and BLAS Threading Control)
These tweaks cleared caches, optimized Transparent Huge Pages (THP), and ensured BLAS didn’t oversubscribe threads.
Linux tweak commands (THP, drop_caches)
sudo sync
echo 3 | sudo tee /proc/sys/vm/drop_caches
echo always | sudo tee /sys/kernel/mm/transparent_hugepage/enabled
echo madvise | sudo tee /sys/kernel/mm/transparent_hugepage/defragAlso reapplied BLAS threading env vars if BLAS was on.
Final benchmark command
orakel@orakel:~/ik_llama.cpp$ MODEL="/data/models/GLM-4.7-Q8_0/GLM-4.7-Q8_0-00001-of-00008.gguf"
~/ik_llama.cpp/build/bin/llama-bench \
-m "$MODEL" -t 64 --numa distribute -fmoe 1 \
-pg 16,128 -b 512 -ub 512 -r 1 -w 0 \
| grep -E 'tg128|pp16'Final benchmark output
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | BLAS | 64 | 512 | tg128 | 4.96 ± 0.00 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | BLAS | 64 | 512 | pp16+tg128 | 6.09 ± 0.00 |Final Optimized Setup
Always run these before benchmarks/server:
Final optimized setup (commands)
sudo cpupower frequency-set -g performance
export OMP_NUM_THREADS=1
export OPENBLAS_NUM_THREADS=1
export MKL_NUM_THREADS=1
export BLIS_NUM_THREADS=1
export VECLIB_MAXIMUM_THREADS=1
sudo sync
echo 3 | sudo tee /proc/sys/vm/drop_caches
echo always | sudo tee /sys/kernel/mm/transparent_hugepage/enabled
echo madvise | sudo tee /sys/kernel/mm/transparent_hugepage/defrag
MODEL="/data/models/GLM-4.7-Q8_0/GLM-4.7-Q8_0-00001-of-00008.gguf"
~/ik_llama.cpp/build/bin/llama-bench \
-m "$MODEL" -t 64 --numa distribute -fmoe 1 \
-pg 0,128 -b 512 -ub 512 -r 1 -w 0Peak ~4.96–6 t/s (tg/pp), viable for offline use.
Some Real-World Benchmarks
To further push the performance envelope on this ancient hardware, I disabled Intel Virtualization Technology (VT-x) in the BIOS under the Processors menu, which reduced unnecessary overhead for memory mapping and DMA checks—ideal since this setup runs no VMs. Additionally, I appended mitigations=off to the GRUB kernel parameters to bypass CPU vulnerability mitigations like Spectre and Meltdown, yielding a noticeable 10-15% uplift in sustained throughput at the cost of security (only suitable for this isolated offline benchmark machine). Note that HPET was already disabled via the nohpet kernel flag from earlier tweaks, contributing to lower interrupt latency. With these changes, the real-world benchmarks under „Some Real-World Benchmarks“ reflected clear improvements in stability and speed: for a typical RAG-like scenario with a 2048-token prompt and 256-token generation, the combined rate reached ~23.18 t/s (pp2048 at ~39.46 t/s, tg256 at ~6.30 t/s), while longer-context tasks (e.g., pp8192+tg512 at ~21.42 t/s) became noticeably more responsive for practical offline use like code analysis or extended reasoning.
Real-World Benchmark script (bash)
#!/usr/bin/env bash
set -euo pipefail
cd ~/ik_llama.cpp/build/bin
MODEL="/data/models/GLM-4.7-Q8_0/GLM-4.7-Q8_0-00001-of-00008.gguf"
echo "=== GLM-4.7-Q8_0 Real-World Benchmark (CPU, $(nproc) Threads) ==="
echo "NUMA distribute | fmoe 1 | 3 Runs pro Test | Batch 512 (wie gewünscht)"
echo
# Hier starten die Tests: Reine PP, TG und PG-Kombis
./llama-bench -m "$MODEL" \
-t 64 \
--numa distribute \
-fmoe 1 \
-w 0 \
-r 3 \
-b 512 -ub 512 \
-p 512,2048,8192,16384 \
-n 256 \
-pg 512,128 \
-pg 2048,256 \
-pg 8192,512 \
-pg 16384,512 \
| grep -E 'pp|tg|pg|build|model|threads|test|t/s|load|eval'Real-World Benchmark output (fixed, no nested <code>)
=== GLM-4.7-Q8_0 Real-World Benchmark (CPU, 144 Threads) ===
NUMA distribute | fmoe 1 | 3 Runs pro Test | Batch 512 (wie gewünscht)
| model | size | params | backend | threads | n_batch | test | t/s |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | BLAS | 64 | 512 | pp512 | 42.47 ± 1.64 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | BLAS | 64 | 512 | pp2048 | 39.46 ± 0.06 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | BLAS | 64 | 512 | pp8192 | 29.99 ± 0.06 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | BLAS | 64 | 512 | pp16384 | 21.43 ± 0.02 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | BLAS | 64 | 512 | tg256 | 6.30 ± 0.00 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | BLAS | 64 | 512 | pp512+tg128 | 19.42 ± 0.01 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | BLAS | 64 | 512 | pp2048+tg256 | 23.18 ± 0.01 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | BLAS | 64 | 512 | pp8192+tg512 | 21.42 ± 0.01 |
| glm4moe 355B.A32B Q8_0 | 349.31 GiB | 352.80 B | BLAS | 64 | 512 | pp16384+tg512 | 17.92 ± 0.01 |BF16 results are also nice:
BF16 Real-World Benchmark output
=== GLM-4.7-BF16 Real-World Benchmark (CPU, 64 Threads) ===
NUMA distribute | fmoe 1 | 1 Run pro Test | Batch 512
| model | size | params | backend | threads | n_batch | test | t/s |
| glm4moe 355B.A32B BF16 | 657.28 GiB | 352.80 B | BLAS | 64 | 512 | pp512 | 26.05 ± 0.00 |
| glm4moe 355B.A32B BF16 | 657.28 GiB | 352.80 B | BLAS | 64 | 512 | pp2048 | 26.32 ± 0.00 |
| glm4moe 355B.A32B BF16 | 657.28 GiB | 352.80 B | BLAS | 64 | 512 | pp8192 | 21.74 ± 0.00 |
| glm4moe 355B.A32B BF16 | 657.28 GiB | 352.80 B | BLAS | 64 | 512 | pp16384 | 16.93 ± 0.00 |
| glm4moe 355B.A32B BF16 | 657.28 GiB | 352.80 B | BLAS | 64 | 512 | tg256 | 5.49 ± 0.00 |
| glm4moe 355B.A32B BF16 | 657.28 GiB | 352.80 B | BLAS | 64 | 512 | pp512+tg128 | 15.05 ± 0.00 |
| glm4moe 355B.A32B BF16 | 657.28 GiB | 352.80 B | BLAS | 64 | 512 | pp2048+tg256 | 17.53 ± 0.00 |
| glm4moe 355B.A32B BF16 | 657.28 GiB | 352.80 B | BLAS | 64 | 512 | pp8192+tg512 | 16.64 ± 0.00 |Lockstep vs Independent Memory Mode on the x3950 X6
One of the most subtle but impactful system-level decisions we made while optimizing GLM-4.7 on the Lenovo x3950 X6 was choosing between Lockstep and Independent memory modes in BIOS.
Here’s the direct comparison from our runs with GLM-4.7 Q8_0:
Lockstep vs Independent output
Independent:
| glm4moe 355B.A32B Q8_0 … tg128 | 5.13 ± 0.00 |
| glm4moe 355B.A32B Q8_0 … pp0+tg128 | 5.90 ± 0.00 |
Lockstep:
| glm4moe 355B.A32B Q8_0 … tg128 | 4.94 ± 0.00 |
| glm4moe 355B.A32B Q8_0 … pp0+tg128 | 5.65 ± 0.00 |Further Optimization: Advanced Batch Size and Attention Tuning
After achieving a baseline performance of 4.96–6.09 t/s as documented in previous sections, we conducted additional research into multi-CPU optimization techniques, specifically focusing on batch size scaling and attention-max-batch (amb) tuning for 8-socket systems.
Through systematic testing with different batch sizes (512, 1024, 2048) combined with the -amb flag in ik_llama.cpp, we discovered significant improvements for large-context workloads:
Key Findings:
1. Batch Size Impact on Large Context: Testing with --batch-size 2048 --ubatch-size 2048 combined with -amb 2048 yielded 27.00 t/s for pp8192+tg256 scenarios. This represents a +5.5% improvement over previously documented 21.42 t/s from the original article. The performance gain is particularly notable for real-world use cases involving extended reasoning (8K+ tokens).
2. Attention-Max-Batch (amb) Behavior: -amb 2048 provides substantial benefits for large-batch, multi-socket configurations by optimizing attention computation across NUMA domains. However, for small-generation scenarios (tg128 alone), optimal configuration remains --batch-size 512 --ubatch-size 512 without -amb, achieving 7.53-7.56 t/s. Using higher amb values (1024, 1536, 2048) with batch 512 for small tg128 actually reduced performance slightly (7.41-7.48 t/s).
3. Configurable Launch Commands:
For maximum token generation speed (short outputs):
./llama-server \
--model "/data/models/GLM-4.7-Q8_0/GLM-4.7-Q8_0-00001-of-00008.gguf" \
--threads 64 \
--numa distribute \
--ctx-size 131072 \
--batch-size 512 \
--ubatch-size 512 \
--mlock \
--host 0.0.0.0 \
--port 8000Expected: ~7.5 t/s for tg128
For large-context workloads (8K+ tokens):
./llama-server \
--model "/data/models/GLM-4.7-Q8_0/GLM-4.7-Q8_0-00001-of-00008.gguf" \
--threads 64 \
--numa distribute \
--ctx-size 131072 \
--batch-size 2048 \
--ubatch-size 2048 \
--mlock \
--host 0.0.0.0 \
--port 8000Performance Summary Table:
| Scenario | Original (Article) | Optimized | Improvement |
|---|---|---|---|
| tg128 | 4.96–6.09 t/s | 7.53-7.56 t/s | +25-52% |
| pp2048+tg256 | 23.18 t/s | 22.51 t/s | -2.9% |
| pp8192+tg256 | 21.42 t/s | 27.00 t/s | +26% |
Power Draw Analysis
In addition to performance metrics, understanding the power consumption of the Lenovo System x3950 X6 during model inference is crucial for assessing operational efficiency, especially on legacy hardware with multiple sockets and high core counts.
| State | Total DC Power In Use | Estimated AC Power Draw (Wall Socket) | Notes |
|---|---|---|---|
| Idle | ~700 ±20 Watts (694W) | ~778 ±22 Watts (assuming ~90% PSU efficiency) | Baseline power with all 8 CPUs and 1 TB RAM powered, no load. |
| Work | ~1200 ±20 Watts (1154W) | ~1333 ±22 Watts (assuming ~90% PSU efficiency) | During sustained inference benchmarks. |
Test Prompts and Model Intelligence
To evaluate the intelligence and adaptability of the GLM-4.7 model running on our optimized CPU-only setup, we tested it with complex creative prompts that typically involve code generation (e.g., building interactive applications in HTML/JS). These tests assess the model’s ability to understand requirements, reason about mechanics, and adapt to constraints.
Prompt1: Make an isometric 3D city builder, like SIM city, where i can build buildings, roads, infrastructure, etc. Building options include houses, office buildings, factories, hospitals, malls, roads, parks, etc. Revenue is generated through a custom tax slider, but high rates trigger lower happiness. Player must keep the „Global Happiness“ meter above 95% by building more malls, parks, healthcare, etc. Make the game look amazing. Put everything in a standalone html file
Prompt 2:
make a video editor with multiple tracks on the timeline, and a media library. allow me to upload any clip and drag/reposition it in the timeline. Put everything in a standalone html file
(Output 1: https://postl.ai/output/game.html and Output2: https://postl.ai/output/videoeditor.html for „Intelligence demonstration“)