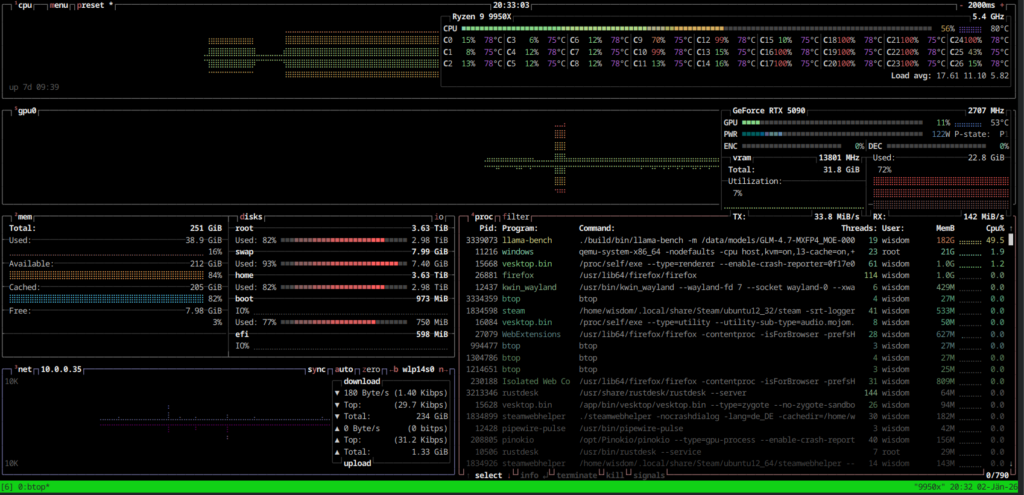
Benchmark: GLM-4.7 MXFP4 and abliterated Q4_0 on 9950x+256GB 6000MT/s+RTX5090
Squeezing Maximum Performance from a 355B MoE Model – A Practical Benchmark Guide
Introduction
GLM-4.7 is an impressive open-source MoE (Mixture of Experts) model with 400 billion parameters that can run on consumer hardware thanks to its architecture. In this comprehensive benchmark, I’ll show how I achieved 619 tokens per second for prompt processing and a stable 6.17 t/s for token generation on my system.
Hardware Setup
(base) wisdom@9950x:/data/models$ fastfetch
.',;::::;,'. wisdom@9950x
.';:cccccccccccc:;,. ------------
.;cccccccccccccccccccccc;. OS: Fedora Linux 43 (KDE Plasma Desktop Edition) x86_64
.:cccccccccccccccccccccccccc:. Host: X870E AORUS PRO (Default string-CF-WCP-ADO)
.;ccccccccccccc;.:dddl:.;ccccccc;. Kernel: Linux 6.17.12-300.fc43.x86_64
.:ccccccccccccc;OWMKOOXMWd;ccccccc:. Uptime: 7 days, 10 hours, 20 mins
.:ccccccccccccc;KMMc;cc;xMMc;ccccccc:. Packages: 4485 (rpm), 64 (flatpak), 8 (snap)
,cccccccccccccc;MMM.;cc;;WW:;cccccccc, Shell: bash 5.3.0
:cccccccccccccc;MMM.;cccccccccccccccc: Display (OLED G42P5): 3840x2160 @ 138 Hz (as 3072x1728) in 48" [External, HDR] *
:ccccccc;oxOOOo;MMM000k.;cccccccccccc: Display (HP E243i): 1200x1920 @ 60 Hz (as 960x1536) in 24" [External]
cccccc;0MMKxdd:;MMMkddc.;cccccccccccc; DE: KDE Plasma 6.5.4
ccccc;XMO';cccc;MMM.;cccccccccccccccc' WM: KWin (Wayland)
ccccc;MMo;ccccc;MMW.;ccccccccccccccc; WM Theme: Breeze
ccccc;0MNc.ccc.xMMd;ccccccccccccccc; Theme: Breeze (Light) [Qt], Breeze [GTK3]
cccccc;dNMWXXXWM0:;cccccccccccccc:, Icons: Breeze [Qt], breeze-dark [GTK3/4]
cccccccc;.:odl:.;cccccccccccccc:,. Font: Noto Sans (10pt) [Qt], Noto Sans (10pt) [GTK3/4]
ccccccccccccccccccccccccccccc:'. Cursor: Breeze (24px)
:ccccccccccccccccccccccc:;,.. Terminal: /dev/pts/1
':cccccccccccccccc::;,. CPU: AMD Ryzen 9 9950X (32) @ 5.76 GHz
GPU: NVIDIA GeForce RTX 5090 [Discrete]
Memory: 39.70 GiB / 251.30 GiB (16%)
Swap: 7.41 GiB / 8.00 GiB (93%)
Disk (/): 2.98 TiB / 3.64 TiB (82%) - btrfs
Disk (/data): 2.62 TiB / 3.58 TiB (73%) - ext4
Local IP (enp15s0): 10.0.0.19/24
Locale: de_AT.UTF-8
(base) wisdom@9950x:/data/models$
Models Tested
1. GLM-4.7-MXFP4_MOE
- Size: 183 GB (12 GGUF shards)
- Quantization: MXFP4 (Microscaling FP4)
- Inference Engine: ik_llama.cpp
2. Huihui-GLM-4.7-abliterated-Q4_0
- Size: 188 GB (21 GGUF shards)
- Quantization: Q4_0
- Inference Engine: llama.cpp
The Key to Success: MoE Layer Offloading
The secret to high performance with MoE models lies in intelligent offloading of expert layers. Instead of the classic -ncmoe parameter, I use the -ot (Override Tensor) parameter:
-ot '.*ffn_(up|down|gate)_exps\.weight=CPU'This regex pattern specifically moves the MoE expert weights to the CPU while keeping all other layers on the GPU. The result: Significantly higher ngl values without out-of-memory errors.
Comparison: ncmoe vs. -ot Parameter
| Method | Max ngl | PP (t/s) | TG (t/s) |
|---|---|---|---|
-ncmoe 999 | 32 | ~65 | ~5.1 |
-ot Pattern | 112 | ~87 | ~6.2 |
Conclusion: The -ot parameter enables almost 4x higher GPU layer utilization!
Detailed Benchmark Results
MXFP4 with ik_llama.cpp – Top Results
Small Prompts (PP=512, TG=128)
| model | size | params | backend | ngl | threads | test | t/s |
| --------------------- | ---------: | ---------: | ------- | --: | ------: | ------: | ----------: |
| glm4 MXFP4_MOE | 182.92 GiB | 404.87 B | CUDA | 112 | 16 | pp512 | 87.47 ± 0.00 |
| glm4 MXFP4_MOE | 182.92 GiB | 404.87 B | CUDA | 112 | 16 | tg128 | 6.25 ± 0.00 |Medium Prompts (PP=4096, TG=512)
| model | size | params | backend | ngl | threads | test | t/s |
| --------------------- | ---------: | ---------: | ------- | --: | ------: | ------: | -----------: |
| glm4 MXFP4_MOE | 182.92 GiB | 404.87 B | CUDA | 112 | 16 | pp4096 | 401.72 ± 0.00 |
| glm4 MXFP4_MOE | 182.92 GiB | 404.87 B | CUDA | 112 | 16 | tg512 | 6.21 ± 0.00 |Large Prompts (PP=16384, TG=2048)
| model | size | params | backend | ngl | threads | test | t/s |
| --------------------- | ---------: | ---------: | ------- | --: | ------: | ------: | -----------: |
| glm4 MXFP4_MOE | 182.92 GiB | 404.87 B | CUDA | 112 | 16 | pp16384 | 619.54 ± 0.00 |
| glm4 MXFP4_MOE | 182.92 GiB | 404.87 B | CUDA | 112 | 16 | tg2048 | 6.17 ± 0.00 |Huihui Q4_0 with llama.cpp – Top Results
Large Prompts (PP=16384, TG=2048)
| model | size | params | backend | ngl | fa | threads | test | t/s |
| --------------------- | ---------: | ---------: | ------- | --: | -: | ------: | ------: | -----------: |
| glm4 Q4_0 | 187.56 GiB | 404.87 B | CUDA | 96 | 1 | 16 | pp16384 | 599.51 ± 0.00 |
| glm4 Q4_0 | 187.56 GiB | 404.87 B | CUDA | 96 | 1 | 16 | tg2048 | 6.10 ± 0.00 |Performance Scaling by Prompt Size
An interesting finding: PP performance scales significantly with prompt size, while TG remains constant:
| Prompt Size | PP (t/s) | TG (t/s) | PP Efficiency |
|---|---|---|---|
| 512 Tokens | 87.47 | 6.25 | Baseline |
| 1024 Tokens | 123.60 | 6.23 | +41% |
| 2048 Tokens | 228.69 | 6.22 | +161% |
| 4096 Tokens | 401.72 | 6.21 | +359% |
| 8192 Tokens | 512.38 | 6.19 | +486% |
| 16384 Tokens | 619.54 | 6.17 | +608% |
Key Insight: For applications with large contexts (code analysis, document processing), the model reaches its maximum efficiency. Token generation remains constant at ~6.2 t/s.
ik_llama vs. llama.cpp Comparison
For MXFP4 models, ik_llama.cpp (a fork of llama.cpp with additional optimizations) offers significant advantages:
| Engine | Model | PP (512) | PP (16K) | TG |
|---|---|---|---|---|
| ik_llama | MXFP4 | 87.47 | 619.54 | 6.25 |
| llama.cpp | Q4_0 | 67.38 | 599.51 | 6.10 |
ik_llama advantage: ~30% faster prompt processing for small prompts, ~3% for large prompts.
Optimal Parameter Configuration
For MXFP4 (ik_llama.cpp)
llama-bench \
-m GLM-4.7-MXFP4_MOE.gguf \
-t 16 \
-ngl 112 \
-gr 1 \
-ot '.*ffn_(up|down|gate)_exps\.weight=CPU' \
-b 16384 -ub 8192 \
-ctk q4_0 -ctv q4_0 \
--numa distributeFor Q4_0 (llama.cpp)
llama-bench \
-m Huihui-GLM-4.7-abliterated-Q4_0.gguf \
-t 16 \
-ngl 96 \
-fa 1 \
-ot '.*ffn_(up|down|gate)_exps\.weight=CPU' \
-b 8192 -ub 4096 \
-ctk q4_0 -ctv q4_0 \
--numa distributeParameter Reference
| Parameter | Value | Description |
|---|---|---|
-t 16 | 16 Threads | Optimal for 9950X (more = worse TG!) |
-ngl 112/96 | GPU Layers | Maximum without OOM thanks to -ot |
-gr 1 | Graph Reuse | ik_llama specific, improves PP |
-fa 1 | Flash Attention | llama.cpp specific |
-ot '...' | MoE to CPU | Enables high ngl values |
-b/-ub | Batch Sizes | Larger = better PP for large prompts |
-ctk/-ctv q4_0 | KV Cache | Quantized for large contexts |
--numa distribute | NUMA | Optimal RAM distribution |
Key Findings
1. Thread Count is Critical
More threads ≠ better performance! At T=32, TG performance drops dramatically:
| Threads | PP (t/s) | TG (t/s) |
|---|---|---|
| 16 | 67.38 | 6.10 |
| 24 | 68.12 | 5.41 |
| 32 | 65.89 | 3.82 |
16 threads are optimal for the Ryzen 9 9950X.
2. KV Cache Quantization
For large contexts (>32K), q4_0 KV cache is essential:
- f16 KV: OOM at 16K+ context
- q4_0 KV: Stable up to 128K context
3. Batch Size by Application
- Small prompts (<2K): B=4096, UB=2048
- Large prompts (>4K): B=16384, UB=8192
Realistic Workload Scenarios
For practical coding assistant scenarios:
| Scenario | Prompt | Generation | PP (t/s) | TG (t/s) | Wait Time* |
|---|---|---|---|---|---|
| Quick Question | 512 | 256 | 87 | 6.2 | ~47s |
| Code Review | 4096 | 512 | 402 | 6.2 | ~93s |
| Large Codebase | 16384 | 1024 | 619 | 6.2 | ~192s |
| Maximum Context | 32768 | 2048 | ~620 | 6.2 | ~383s |
*Estimated total time for prompt processing + token generation
Conclusion
GLM-4.7 runs impressively on consumer hardware. With the right optimizations, you can achieve:
- 619 t/s prompt processing for large contexts
- Stable 6.2 t/s token generation regardless of context size
- Up to 128K context with q4_0 KV cache
The key lies in intelligent MoE offloading via the -ot parameter and finding the right balance between GPU layers, thread count, and batch sizes.
For coding assistant applications, the TG rate of 6.2 t/s (~370 words/minute) is absolutely practical – comparable to the reading speed of a fast reader.
Download Links
- GLM-4.7-MXFP4_MOE: Hugging Face
- Huihui-GLM-4.7-abliterated: Hugging Face
- ik_llama.cpp: GitHub
- llama.cpp: GitHub